Why LLM watermarking will never work
Have you heard the claim that “watermarking can help identify text generated by an LLM”? Or that “watermarking can help reduce harms like AI-generated misinformation”?
In this post, I’ll guide you through a set of thought experiments that demonstrate why watermarking can’t live up to these claims. For this journey you won’t need technical knowledge of watermarking, just your common sense and the ability to reason.
If you’re a policy maker in a hurry and want to check that your understanding of watermarking aligns with reality, you can scroll down to the final “Questions” section and see if you have a good answer for each of them.
What is watermarking?
Watermarking (specifically, statistical watermarking of LLM text) is a process applied when generating a response from an LLM.
A contrived watermarking scheme might work like this: when generating each word in a response, if the previous word started with a letter that was an even number in the alphabet (B, D, F, etc) then show a slight preference for selecting words starting with an odd-numbered letter (A, C, E, etc). You can then run any piece of text through a detection algorithm and it will tell you with some confidence whether the text has this particular ‘watermark’ (a pattern of words).
Real-world strategies are more sophisticated (and operate on tokens, not words), but hopefully this gives you an idea of how an LLM can produce text that appears natural to humans, but can be detected as ‘synthetic’ when you know what to look for.
So, we can identify text from an LLM?
The driving idea behind watermarking is that it ‘can help identify text generated by an LLM’.
That word ‘an’ hides some serious ambiguity, and depending on how you interpret ‘an LLM’, you might imagine that watermarking achieves one of two goals:
- Identify text generated by a particular, watermarked LLM
- Distinguish between AI-generated and human-generated text
Watermarking addresses the first point, but is often spoken about as though it achieves the second.
The first case might be useful to LLM developers. The second is useful to society, because it can help protect the public from various AI-enabled harms (in theory).
When I make the claim that watermarking “will never work”, I mean that it will never solve the problem of distinguishing between AI-generated and human-generated text, and by extension, that watermarking can’t work as a way to prevent the societal harms enabled by AI-generated text.
You may wonder if this is a strawman argument. It isn’t. The claim that ‘watermarking can help identify text generated by an LLM’ is put forward in every paper I’ve read on the topic (1, 2, 3, 4, 5, 6). And most of these papers go on to make the stronger (and wronger) claim that watermarking can help reduce harm in some way. That’s the message from researchers, if we turn our attention to articles in the media covering the latest watermarking paper (from DeepMind, published in Nature) they all mention watermarking’s ability to detect AI-generated content and reduce harm (1, 2, 3, 4, 5, 6). And none mention the reasons watermarking will never work. So it’s clear that many people hold an incorrect view of watermarking’s potential.
Why will watermarking never work?
For watermarking to enable distinguishing AI text from human text, there are three conditions that must be met. I’ll explain why each of these is required in the following sections. The conditions are:
- All capable LLMs implement watermarking
- No LLM providers allow control over token selection
- No open source models exist
Let’s look at each condition in detail.
1. All capable LLMs implement watermarking
By ‘capable’ I mean any LLM able to produce the harmful outcomes that watermarking is intended to prevent.
You might be wary of me using a phrase like ‘never work’ (a good instinct!). But I can tell you that this particular condition is categorically impossible simply because capable open source models without watermarking already exist. LLMs like Llama 3.1 405B have been downloaded millions of times already, and these un-watermarked models can’t be un-downloaded.
You could stop reading here, really. This alone is enough to explain why watermarking will never work: people wishing to cause harm will always have access to capable, unwatermarked LLMs.
If this isn’t clear, a visualisation might help. The below diagram illustrates three scenarios (rows) in a simplified LLM landscape. The columns represent sources of text, blue blocks represent watermarked content.
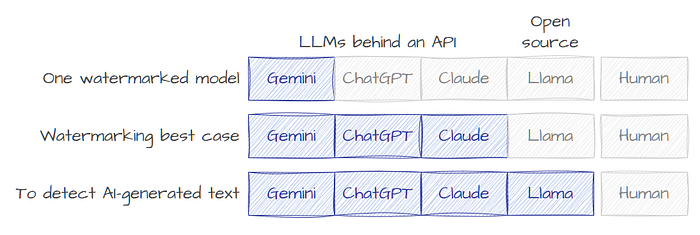
The top row is our current state, with one watermarked LLM. The second row is the best possible future state for watermarking (most LLMs are watermarked, but you can’t watermark existing open models). The third row is what it would look like to differentiate between AI-generated and human content, but this is not possible.
Unfortunately, the language used to discuss watermarking often fails to distinguish between ‘some’ and ‘all’ AI-generated text, and all three scenarios can technically be described as ‘detecting AI-generated text’.
You might say this is just semantics. But detecting AI-generated text is the sort of problem where you have to solve it for all LLMs, or you haven’t solved anything.
If you had a house with four windows and you only locked one of them, would you say that this ‘helps secure your home’? What if you knew that some of the other windows could never be locked? What if burglars knew in advance which windows would be unlocked?
2. No LLM providers allow control over token selection
When thinking carefully about a problem, I like to use the thought template “if X is true, what else must be true?” and immerse myself in a hypothetical world where X is true. This helps when reasoning about the plausibility of a claim or goal. In this case, we can ask: in a world where all LLMs are watermarked, what else must be true?
Pondering this for a while leads to a few realisations…
First, in a world where all LLM outputs must be watermarked, an LLM provider couldn’t allow users to set temperature to 0. If you’re not familiar with ‘temperature’ as it pertains to LLMs, you can think of it like ‘randomness’. All you need to know is that sometimes a bit of randomness can be good, but at other times you need to set it to zero, like when you want the same input to always result in the same output, or when generating code or data in a strict format. You also need to know that the concept of statistical watermarking relies on a bit of randomness, and isn’t possible if the temperature is 0. (The same is true of ‘top P’ for similar reasons.)
Secondly, in a world where all outputs must be watermarked, an LLM provider couldn’t allow users to access alternate selections for each token, as OpenAI does via the top_logprobs parameter. It’s OK if you don’t know what ‘top log probs’ are, just know that they’re a useful feature that would need to be removed if OpenAI wanted all outputs to be watermarked.
So if you envision a future where all AI-generated text is watermarked, then you must also envision a future without access to temperature, top_p, or top_logprobs.
This is quite problematic, because there are existing harm-reduction systems out there (content moderation, fraud detection, vulnerability-finding systems, etc) that could lose effectiveness if reducing temperature was outlawed. So ironically, if you wanted to mandate watermarking to reduce harm, a side effect would quite possibly be an increase in harm as existing systems are forced to operate with reduced effectiveness.
Fortunately, the probability of this condition ever being met is surely near zero.
3. No open source models exist
I’ve said ‘open source’ here, but more specifically I’m referring to models that can be downloaded and run on the user’s own hardware, as opposed to models served from behind an API.
Watermarks are applied at generation time. That is, the process happens outside the black box magic of a model’s weights, in the regular code that selects tokens based on the model’s outputs. The watermarking mechanism is therefore trivial to remove from open source models (just delete the code that adds the watermark), which means watermarking only really makes sense when implemented behind an API, where it can be enforced by the LLM provider.
(I suspect that many people formed their opinion of watermarking back when all the capable LLMs were behind APIs, and are yet to update their views. Perhaps they’re updating as they read these very words…)
So, if you want a world with watermarking, you need a world without open source (downloadable) models.
Also consider that savvy malicious users will know that if they use an LLM behind an API, they’re likely being watched (OpenAI reports on nefarious accounts they’ve blocked, and describes how different tech companies share information to track malicious users across platforms). So malicious users will prefer open source models for the privacy, regardless of watermarking. But open source models are just the place where watermarking doesn’t make sense!
Now, some folks might claim that open source models are not quite as good as proprietary models, and thus have less potential for harm. Perhaps only future, API-based LLMs will be powerful enough to cause real harm, so we don’t need to worry about watermarking the open source models. Even if this is true, it doesn’t help the case for watermarking, because you can remove a watermark from a more powerful model by paraphrasing the output with an open source model. And smarter LLMs won’t require smarter paraphrasing to remove the watermark, today’s models will always be good enough, no matter what the future brings.
Some might say yes yes, watermarking can be worked around by paraphrasing, but it’s still a deterrent. I would politely request quantification of this assertion: what percentage of people with bad intentions will be deterred and how much wishful thinking was involved in the fabrication of that statistic?
Secondly, if you’re happy with a mere ‘deterrent’, then oh boy, do I have a watermarking scheme for you! It works like this: in the LLM output, just replace regular space characters with the ‘en space’ character. They look the same to humans, but are detectably different. This might seem like a trivial example, but even the most advanced watermarking techniques are barely more robust than space-replacing. In both cases, an LLM provider can claim that their content can be detected as AI-generated, but in both cases, malicious users will simply work around it and you’ve achieved very little in real-world harm reduction.
To be clear, this third condition (no open source models) is subtly different to the first (all LLMs are watermarked). The first simply points out that we can’t go back in time: we already have LLMs that aren’t watermarked and that can’t be undone. This third condition states that we can’t have LLMs that users are free to download and modify.
So, I’ve put forward a case for why watermarking will never work as a means to detect AI-generated text, and I hope you can clearly see the insurmountable problems with the idea.
At this point, you might want to take a step back and wonder: if not watermarking, what other technical solutions could we investigate to reach our goal of detecting AI text?
This is a good thing to wonder, but I’d suggest taking just one more step back and asking: does the goal of detecting AI-generated text make sense?
Does detecting AI-generated text make sense?
To explore this, let’s imagine we’re in an alternate universe where all AI-generated text is watermarked and detectable, no exceptions. This would seem like a win, right? A goal reached, a hard problem solved.
But when you think it through, it becomes clear that this doesn’t actually solve any problems, and that ‘detecting AI-generated text’ is not a desirable goal.
There are two issues we need to consider:
- The distinction between AI text and human text is not binary
- ‘AI-generated’ and ‘harmful’ are not the same thing
Let’s look at each of these in detail.
1. It’s not a binary question
A human can write a piece of text and ask an LLM to tidy it up for them (I wish more people did). An LLM could summarise several human-written sources and report on common themes. A scientist could write a paper in Estonian and have an LLM translate it to English for publication.
In all such cases, the underlying thoughts and concepts are human, they’re just organised or rearranged by AI. Does this count as ‘AI-generated’? (Consider both your own personal answer to this question, and the fact that not everyone will agree.)
As LLMs get better and more people realise the benefits of using AI to help with their writing (and thinking), more and more content will be touched by AI in some way.
So it’s not a binary distinction and it’s only going to get less binary.
This is a common cause of bad solutions: to treat a mostly binary system as though it were a strictly binary system (often because binary outputs would be convenient — ‘if the submitted paper has an LLM watermark, reject it’). These solutions look OK at first glance, but have undefined behaviour for the ‘exceptions’.
So any line of thinking that involves ‘detecting AI-generated text’ and results in a binary outcome is inherently problematic. You should be wary of anyone proposing the detection of AI text without addressing both the false positives and false negatives that will inevitably occur.
2. Not all AI-generated content is harmful
For any use case where you want to detect AI text, it’s worth thinking about why you want to do that. Your actual goal is likely something slightly different, like reducing misinformation or preventing cheating students.
The Venn diagram of AI-generated content and the harmful content that we want to prevent will look something like this:
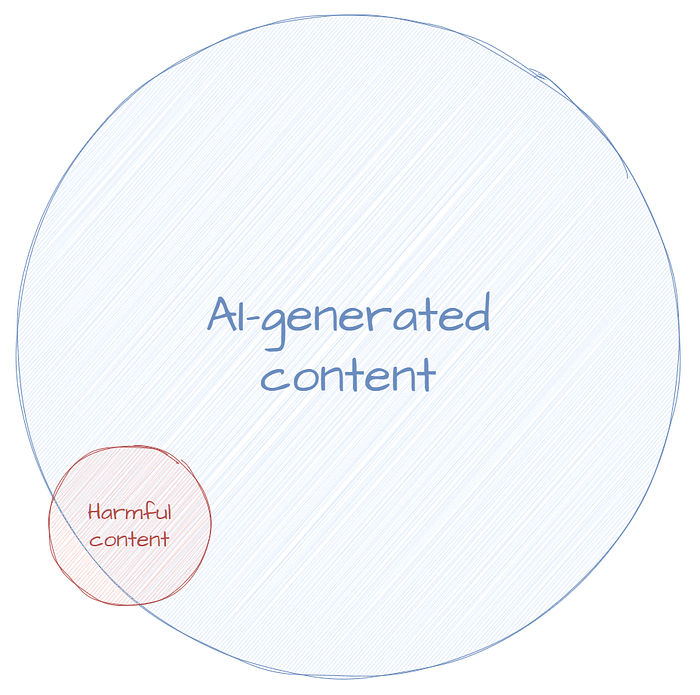
Now, in this post I’ve tried to make assertions that are easy to agree with (you can’t un-exist open source LLMs, etc). But now I’ve gone and chosen sizes for two circles in a Venn diagram and you might think that I’m wrong and that most AI generated content is harmful. That’s fine. To proceed, all we need to agree on is that not all AI-generated content is harmful, and that not all harmful content is AI-generated.
So, even if we did have the ability to robustly detect AI-generated content, we still have two pretty big questions left over:
- How do we then narrow that down to only the harmful content?
- What about the harmful content that isn’t AI-generated?
This idea — “we need a way to detect AI-generated content” — is the result of what I call ‘goal switching’. When thinking deeply about a problem, I look for signs of goal switching because it’s often an indicator of faulty logic (and wasted effort).
Here’s how goal switching works in this case: we start with several new harms enabled by AI (misinformation, cheating students, etc.) The true goal is to prevent or mitigate these harms. Now, these harms are all enabled by AI-generated content, so it seems reasonable to switch to a proxy goal of ‘detecting AI-generated content’. People then work away toward that proxy goal, in this case by implementing watermarking.
Sometimes goal switching is harmless. But in this case, the switch from the true goal of reducing harm to the proxy goal of detecting AI-generated content was a poor fit (represented by limited overlap in the Venn diagram). So even if we reach the proxy goal, we haven’t actually reduced any harm, the true goal.
As a side note (spicy hot take incoming) this is the same logical error made by any legislation that targets “AI content”. The intent is to reduce harm, but the wording quickly transitions from ‘reducing harm’ to ‘labelling AI-generated content’, as though they’re equivalent.
OK, that was an abstract argument against the logic behind detecting AI-generated text. Let’s now look at a few specific harms that watermarking is supposed to ‘help’ with and see how these themes play out.
Specific claims of harm reduction
(Please continue imagining that we’re in an alternate universe where all AI-generated text is watermarked.)
Misinformation at scale
The risk here is that LLMs enable targeted misinformation at a scale that wasn’t possible before. Detecting AI-generated text seems reasonable at first glance, but the real goal is to prevent the spread of misinformation, whether generated by AI, content farm, or a lone human.
And misinformation is only a subset of all AI text, so once you’ve detected that a piece of text was generated by AI, you still need to solve the problem of detecting whether it’s misinformation or not. There’s a gap between detecting the AI text and actually reducing harm in any way.
Surely a smarter solution is one that detects misinformation.
Labelling AI content on social media
There’s a common belief that AI-generated text is inherently ‘bad’. Even if not overtly stated, any call for labelling in the name of ‘transparency’ implies it.
Certainly some AI-generated content on social media is bad, but there’s plenty of potential for good, too. Any product company could deploy a helper bot to answer users’ questions (wherever they ask them). A university’s marine biology department could launch an agent to answer the web’s shark questions. A Snopes bot could actively fight misinformation by politely responding to falsehoods with the truth, so it’s visible to those who need it most. (AI is much better than humans at politely explaining why something is incorrect.)
As the years roll by, people will come to rely on and enjoy AI-generated content (which is often just remixed human content). If all this content — good and bad — is labelled as ‘AI-generated’, the label will quickly become meaningless because it won’t align with human values like the desire for quality, truth, education, and entertainment.
Meanwhile (back in reality), don’t forget that the malicious folks will bypass watermarking so their text will have an implicit label of ‘human generated’, helping in their deception efforts.
For now, this idea of labelling is merely short-sighted and illogical, but it could be worse. Current regulations only call for the labelling of AI-generated text, but if this goes further and we try to restrict AI text, it could hinder the emergence of beneficial bots. So this simplistic view — bot bad, human good — could cause harm in the long term. We should be seriously questioning any regulation based on this premise (explicitly or otherwise).
Some will argue that labelling is about users having the ‘right to know’ that content wasn’t written by a human. Interesting. Imagine for a moment someone telling you that we have a ‘right to know’ if content was written by a left handed person. You’d ask “why, what’s wrong with them?” Framing this as a ‘right to know’ is just a thin veil over the flawed view that bots are bad and humans are good.
Side note: I think there is merit in knowing whether you’re talking with a human or a bot in a chat environment. You don’t need to watermark text for this, you only need chat bots that don’t identify themselves as human (in some jurisdictions this might be enforceable with existing false advertising laws). Note that in this case, there’s a more solid binary distinction between chatting to a human and a chatbot. And if we think into the future, when bots are better than humans at things like medical advice, then users will want to know that they’re talking with a bot to get the best possible advice. So this is both logical and far-sighted.
Interactive email scams
A serious risk is the use of AI for email scams that can manipulate victims on a scale not previously possible (phishing, money extraction, etc). If well executed, this could cause significant harm (imagine a world where scams aren’t obviously scams, and the scammer is smarter than you).
Detecting AI-generated text seems like it could be useful here, but we have the same problem we had with detecting misinformation; malicious AI text is only a fraction of all AI text, so how exactly do you take that step from “detecting AI-generated text” to “detecting AI-powered scams”?
A better solution would be to detect malicious or deceptive content, regardless of who or what wrote it.
Now, I admit, if I was having an email conversation with my boss and they asked me to move some money from the company account to a bitcoin account, and each of their emails was flagged as AI-generated, this might be enough to make me think twice. So this would be a pretty good idea if you assume that the scammers will happily use watermarked text. But of course, they won’t. They’ll bypass the watermark, and their scam emails will not be labelled as AI-generated.
Students cheating on essays
This final example is a much better fit, and could be the strongest case for watermarking (if it couldn’t be bypassed).
If a teacher has instructed students to complete an essay and told them to not use an LLM, then the overlap of ‘AI text’ and ‘bad behaviour’ is nearly perfect.
But even though checking for AI text would get you mostly true positives (correctly identifying cheaters), you’ll still miss cheaters who didn’t use an LLM, or bypassed the watermark. And you’ll risk wrongly accusing students based on coincidental alignment with a watermark pattern (a serious concern if you apply the test to millions of students and have strong repercussions).
Also, I’d argue that students should use LLMs to help them think through their arguments, to challenge the points of view they’re putting forward, and help them improve their prose. This is now a valuable life skill, so care must be taken to not punish such behaviour.
Now, if you think this cheating scenario through carefully, you’ll find yet another structural problem in the watermarking house of cards…
Whenever there is talk about watermarking content, there needs to be a publicly available system that can detect that watermark. So put yourself in the shoes of a cheating student (in that alternate universe where all LLM output is watermarked). Your goal is to cheat and avoid detection. What would you do? You’d get an LLM to write your (watermarked) essay, change some words, and then use the detection system to check if the watermark can still be detected. If it’s flagged as AI-generated, you’d change it a bit more and check again, and so on. You’re not going to get caught because you’re not going to submit an essay with a detectable watermark.
Before we move on, I’d like to make it clear that I’m not suggesting any of these issues have a simple solution. I’m merely suggesting that detecting AI-generated text is not a solution.
Is watermarking pointless?
The conversation around watermarking reminds me of blockchain. Both are interesting technical feats with plenty of explanations put forward for how they can address various societal issues. But most of those explanations contain faulty logic or are based on false assumptions. And since even reputable sources happily repeat statements that don’t make sense, it’s quite difficult to work out what’s actually true.
With that said, there are several large teams of smart people working on watermarking, so a sensible assumption would be that there is a good reason for watermarking, just not the advertised benefits of harm reduction.
As far as I can tell, the main use case for watermarking is that it allows an LLM developer to detect content made by their LLM, allowing them to identify that text in datasets used for future training runs.
It also allows LLM developers to adhere to regulations like Article 50(2) in the EU AI Act that require watermarking. (I sure hope those regulations weren’t based on the mistaken belief that watermarking can reduce societal harms!)
This leaves us with a bit of a mystery. Why do so many people talk about watermarking as a solution to AI-fuelled societal harms when a few minutes of careful thinking makes it clear that it never will be? Who’s misled and who’s misleading?
If forced to speculate, I would hypothesise that the researchers writing the papers understand the narrow role watermarks play; they want to detect text generated by the LLM that implements the watermark, and know it doesn’t work when temperature is zero, etc. They write up their findings in a paper and then summarise it in an abstract, adding some harm-reduction language to give the paper a broader appeal. Journalists report on the topic and add their own embellishments to portray watermarking as something the average person should care about. By the time the message finds its way to the general public and policy makers, watermarking is presented as a way to distinguish AI text from human text and thus put an end to AI misinformation, cheating on essays, etc.
Perhaps if we had better systems for detecting misinformation, such claims would be caught before they could spread.
By the way, if it seems like I have a vendetta against watermarking, I don’t. I think the technology itself is creative and brilliant — and who doesn’t love a bit of steganography? My issue is with the claim that watermarking can detect AI-generated text (misleading) and reduce harm (dubious, bordering on untrue).
A step in the right direction?
I asked ChatGPT to challenge the arguments I’ve put forward in this post. It assured me that even though watermarking does indeed suffer from all of these weaknesses, it’s a “step in the right direction”.
I picture a person standing on the beach in Sydney, needing to get to LA. As they walk into the ocean, disappearing beneath the waves, they claim that they’re taking a ‘step in the right direction’. Technically right, but fundamentally wrong.
If our goal is to prevent harm (and it is!) a real step in the right direction would focus on the detection and reduction of harmful content, ignoring the ‘AI-generated’ red herring.
Non-text modalities
So far, I’ve spoken entirely of AI-generated text. But does the logic outlined above also apply to watermarking photos and video? Or do these modalities differ conceptually in the context of harm reduction?
It boils down to this: text has only ever been an interpretation of reality, while photos and video are widely considered a representation of reality. Photos and video therefore have a greater potential to mislead because they can be presented (and accepted) as evidence.
I admit to a gut feel that watermarking video in particular has the potential to reduce harm, especially while the most advanced video generation models are behind APIs. But whenever my gut has thoughts, I like to get a second opinion from my brain. And if I think this through from the perspective of a malicious user, I’d simply remove the watermark (by flipping, cropping, resizing, etc.) or use an unwatermarked method like deepfakes.
In reality I think the effect of watermarking will be the same across all modalities: you’re not going to see a watermark on any content produced by a malicious user, because they will have bypassed the watermark, one way or another.
So I don’t see a bright future for watermarking in any modality.
However, unlike the text modality, the goal of distinguishing between real and synthetic images actually makes sense because of their societal role as evidence. But instead of trying to detect the fake content in all its varied forms, the more practical approach is to identify the real content by digitally signing images as they’re captured by a camera’s image sensor. This is called content provenance. As I write this in November 2024, some cameras already support it, and YouTube has started labelling eligible content as ‘captured with a camera’.
This addresses the issue where someone’s bad behaviour is caught on camera, but they dismiss it as a deepfake. (The loss of images as a form of evidence is a greater long term risk than a few people being fooled by fake images.) With content provenance, there will be a signed digital trail proving the image was captured directly to a particular digital camera at a given time and location. (Of course, the wrongdoer can still claim a video was faked in a non-digital way, and their loyal fans will believe them.)
Certainly in the long term, detecting real content appears to be the better solution than trying to watermark all the AI-generated content.
Questions
To wrap up, I’ll restate my main points in the form of questions for proponents of watermarking, especially those involved in crafting regulations to enforce its use:
- Given that capable, unwatermarked open source LLMs already exist — and can’t be retracted — how can watermarking some LLMs be expected to reduce harm? Are you hoping that malicious users won’t take advantage of the unwatermarked LLMs?
- Do you propose that LLM providers eliminate functionality like setting temperature to zero (which prevents watermarking)? If yes, a follow up question: how do you plan to deal with the fallout from all the systems that will stop working reliably at higher temperatures?
- Do you propose a global ban on open source LLMs? If not, how do you plan to ensure watermarks are applied to open source LLMs in a way that can’t be removed?
- Do you propose a publically available watermark detection service? If yes, won’t the malicious users use this to ensure watermarks have been removed successfully (e.g. by paraphrasing with another LLM)?
- If you accept that there are many ways to produce AI-generated text that is not watermarked, but claim that watermarks will still act as a ‘deterrent’, please quantify this. Do you expect watermarking to deter 1% of malicious users? 99%? On what basis? Is the residual harm acceptable, or do you have a plan to tackle that too?
- Where do you draw the line between AI text and human text? Is a news article edited by ChatGPT “AI-generated”? What about an article translated with an LLM? What about an LLM that summarises an article into a tweet on behalf of the author?
- If you were able to reliably detect AI-generated text, how would you then narrow that down to only the harmful content? Follow up question: if you already know how to identify harmful content directly, what’s the point in first identifying AI-generated text?
That’s all folks. Thanks for reading.

